Overview
What is Memory Machine Batch (MMBatch)?
Imagine running a complex, long-running task, like a scientific simulation or a big data analysis. What if it suddenly stops because the computer resources it's using become unavailable? Normally, you'd lose all your progress and have to start over – a huge waste of time and money.
Memory Machine Batch (MMBatch) solves this problem. It's a smart tool that works with your cloud provider's Batch service (like AWS Batch) to make your jobs more reliable and cost-effective.
Here's how MMBatch helps you:
- Never Lose Progress: MMBatch regularly takes a complete snapshot of your running job, including all its memory and data. If the job's underlying computer shuts down unexpectedly (which can happen with cost-saving "Spot Instances"), MMBatch can instantly restore your job on a new computer right where it left off. You won't lose any of your valuable work!
- Save Money with Spot Instances: Cloud providers offer "Spot Instances" at a much lower cost (sometimes up to 90% less!) than regular computing resources. The catch is that these instances can be reclaimed by the cloud provider with short notice. MMBatch's SpotSurfing feature specifically handles these interruptions on powerful GPU machines, letting you take advantage of these huge cost savings without the risk of losing your critical work.
Key Benefits of MMBatch
- Seamless Integration: MMBatch fits directly into your existing cloud Batch environment without requiring complex changes to your setup.
- Automatic Protection: It automatically handles capturing and restoring your job's progress, so you don't have to manage it manually.
- "SpotSurfing" for GPUs: Specifically designed to keep your GPU-intensive jobs running smoothly even when using the most cost-effective, interruptible Spot Instances.
- No Changes to Your Work: You don't need to modify your existing job applications or workflow scripts. MMBatch works behind the scenes.
- Massive Scalability: Easily handle thousands of batch jobs and hundreds of compute resources, ensuring your large-scale processing runs smoothly.
- Secure Processing: Your data remains secure within your cloud's private network (Virtual Private Cloud - VPC).
To learn more about how MMBatch can optimize your batch processing, visit the MMBatch website.
Supported Clouds and Batch Environment
AWS Batch ECS
Supported Machine Images
- Amazon Linux 2023 with ECS support (kernel 6.1)
- Amazon Linux 2 with ECS support (kernel 5.10)
List of Cloud Service Provider Services Used
| Service | Required/Optional | Usage |
|---|---|---|
| AWS CloudWatch | Optional | MMBatch logging |
| AWS Cognito | Optional | MMBatch Management Server login |
MMBatch Architecture
MMBatch integrates with AWS Batch ECS. The architecture is shown below:
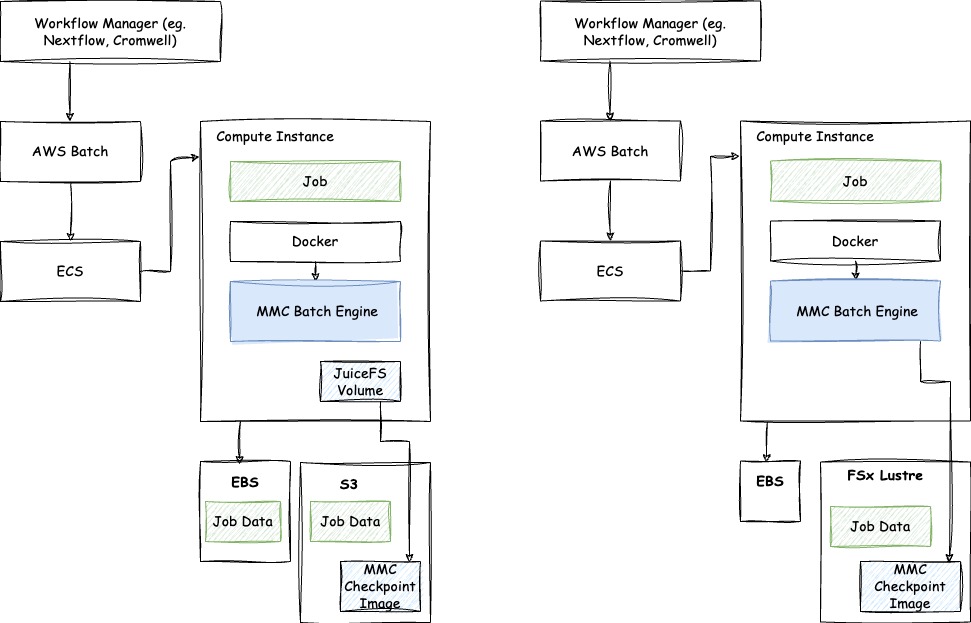
This diagram illustrates two common ways to integrate Memory Machine Batch (MMBatch) into your AWS Batch environment, focusing on how your jobs run and where MMBatch stores its crucial checkpoint images.
Both paths show a Workflow Manager (like Nextflow or Cromwell) submitting jobs to AWS Batch. AWS Batch then uses Amazon ECS to manage the containerized jobs on your Compute Instances. Within each Compute Instance, your Job runs inside a Docker container. This is where MMBatch Engine (the solid blue block) comes into play, ensuring your jobs can resume even after interruptions.
The key difference between the two setups lies in how MMBatch's checkpoint images and your job data are stored:
Left Diagram: Storing Checkpoints on Amazon S3 with JuiceFS
- Job Data Storage: Your job's input and output data (labeled "Job Data") are stored on Amazon EBS (Elastic Block Store) and Amazon S3 (Scalable Storage Service).
- MMBatch Engine: The MMBatch Engine inside the Compute Instance manages the checkpointing process.
- Checkpoint Image Storage: MMBatch creates "Checkpoint Images" (snapshots of your job's progress) and stores them in a dedicated Amazon S3 bucket.
- JuiceFS Integration: To make S3 behave like a traditional file system for the MMBatch Engine, JuiceFS Volume is used. This open-source tool maps file access requests from MMBatch directly to S3's object storage, providing a seamless experience.
Right Diagram: Storing Checkpoints on Amazon FSx for Lustre
- Job Data Storage: In this setup, your job's input and output data (labeled "Job Data") are stored on Amazon FSx for Lustre, a high-performance file system. This is a great choice for workloads requiring very fast access to large datasets.
- MMBatch Engine: As before, the MMBatch Engine inside the Compute Instance handles checkpointing.
- Checkpoint Image Storage: MMBatch saves its "Checkpoint Images" directly to the FSx for Lustre file system, leveraging its speed for quick saves and restores.
- EBS Integration: Amazon EBS is also present, likely providing local storage for temporary files or system data on the Compute Instance.
In both configurations, MMBatch provides its core functionality: capturing the entire running state of your Batch Job into a consistent image and restoring it on a new Compute Instance without losing any work progress. This allows you to leverage cost-effective, interruptible compute resources while maintaining high job reliability.